育休を快適に過ごすために、赤ちゃんのお世話ダッシュボードを作った
目次
はじめに ― なぜ作ったか
現在、子供が生まれてお休みをもらっているところです。この休みの間、赤ちゃんの育児記録には「ぴよログ」を使っています。授乳・おむつ・睡眠のたびに記録できて便利なのですが、
「今何をすべきか」がパッと分からない
という問題があります。前回の授乳から何時間経ったか、次のおむつ替えはいつ頃か。ぴよログの履歴をさかのぼれば分かるのですが、毎回スマホを開いてスクロールするのが手間でした。
そこで、ぴよログのデータをもとに家の中のサーバーで動くダッシュボードを自作することにしました。とりあえず、仮で Baby Dashboardという名前を付けました。この記事ではこのダッシュボートについて簡単に紹介します。
システム全体像
アーキテクチャ
ざっくりとしたアーキテクチャは以下の通り。
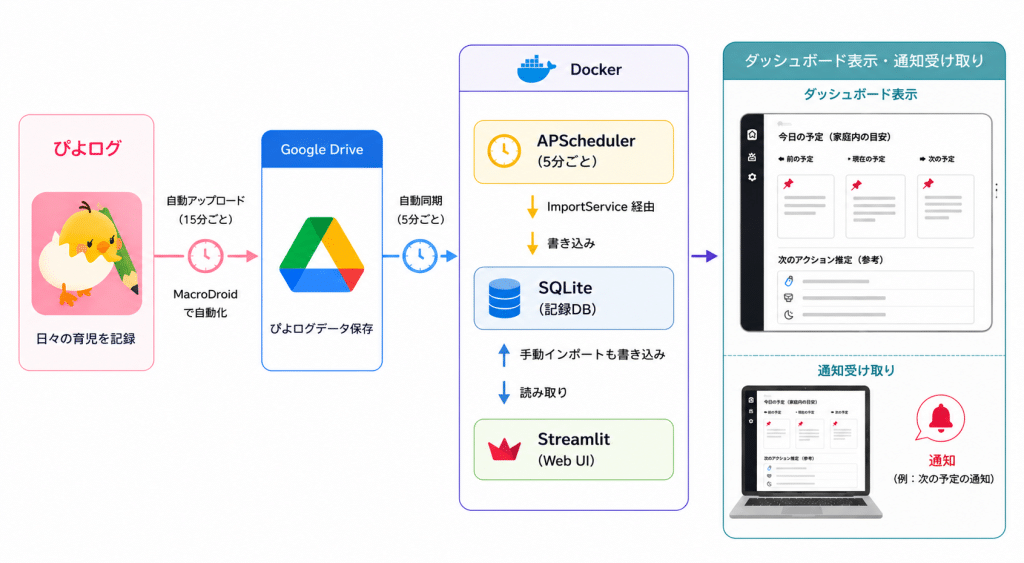
ぴよログはGoogle Driveに上げるには、昔使っていたAndroid端末を利用しました。このAndroid端末からGoogle DriveにMacroDroidを利用して定期的にデータをアップロードし、ダッシュボードのサーバーでGoogle Driveからデータを取り出します。このサーバーはたまたま別件で利用してた家のサーバーで、Docker コンテナとして常時起動しており、同じWi-Fi上のPCやタブレットのブラウザからアクセスできるようにしています。これにより、作業用PCだけでなく、リビングに置いてあるiPadで常にダッシュボードがみれるようにしてあります。
ぴよログからGoogle Driveまでのデータ転送に関しては以下のサイトのやり方を参考にさせていただきました。
https://zenn.dev/big_tanukiudon/articles/52d5a4b653eb47
主な機能
今回作ったダッシュボードの機能は以下の通りです。
| 機能 | 概要 |
|---|---|
| ぴよログインポート | 手動アップロード / Google Drive 自動同期 |
| 経過時間表示 | 最後の授乳・おむつ・睡眠から何時間経ったか |
| 次のアクション予測 | 過去の記録から次回の授乳・睡眠を推定 |
| 1日の予定表示 | 前の予定・現在の予定・次の予定を3カラムで表示 |
| ブラウザ通知 | 予定の5分前にデスクトップ通知 |
とりあえず、最低限これだけあればいいだろうと最初に思い描いたものを作った感じなので、今後追加すると思われます。
ぴよログデータのパースと取り込み
ぴよログにはデータのエクスポート機能があり、日次(1日分)と月次(1ヶ月分)の2種類の形式があります。フォーマットが異なるため、どちらか自動で判定してパースする仕組みを作りました。
フォーマット自動判定
ファイルの先頭数行を読んでヘッダーのパターンから判定します。日次はタイムスタンプが HH:MM 形式で始まり、月次は YYYY/MM/DD 形式で始まります。
class CsvFormatDetector:
@staticmethod
def detect(content: bytes) -> CsvFormat:
# 先頭行のパターンでフォーマットを判定
...ImportService の設計
同じデータを何度インポートしても壊れないように、SHA-256 ハッシュを2段階で計算して管理しています。
- ファイルレベル:
hashlib.sha256(csv_content).hexdigest()でデータファイル全体のハッシュを計算し、同じファイルの再インポートを高速に検出します - レコードレベル:
BabyRecord.generate_content_hash()で各レコードのchild_id | recorded_at | category | amount_ml | sub_category | ended_atを連結してSHA-256ハッシュを計算し、行単位の差分を判定します
インポート結果は3状態で返します。
- 新規: DBにないレコード → 追加
- スキップ: 同じハッシュが既にある → 何もしない
- 削除: 以前のインポートにあったが今回のファイルにはない → 削除
この設計により、ぴよログでデータを修正・追記した最新ファイルを再インポートしても正しく差分が反映されます。
Google Drive 自動同期の実装と落とし穴
ぴよログには Google Drive への自動バックアップ機能があります。これを利用して、ファイルを手動でアップロードしなくても自動で取り込めるようにしました。
仕組み
APScheduler の BackgroundScheduler を使い、5分ごとに Google Drive のフォルダを確認して新しいファイルを取り込みます。
scheduler.add_job(
sync_fn,
trigger="interval",
seconds=300,
next_run_time=datetime.now(timezone.utc), # 起動直後に即時実行
)next_run_time=datetime.now(utc) がポイントで、これを設定しないと APScheduler のデフォルト動作で最初の実行が5分後になってしまいます。
ハマったポイント:15分ごとに新しい file_id でアップロードされる問題
実装してしばらく運用したところ、同日のファイルが何十件もインポートされていることに気づきました。
調べてみると、ぴよログは同じファイル名のファイルを約15分ごとに Google Drive に新規アップロードしていました。Google Drive 上では同名ファイルでも別の file_id が付与されるため、5分ごとに同期が走るたびに「新規ファイル」と判定され、毎回インポートが実行されていました。
【ぴよログ】2026/6/26(金) file_id: abc123 modifiedTime: 22:12
【ぴよログ】2026/6/26(金) file_id: def456 modifiedTime: 22:27
【ぴよログ】2026/6/26(金) file_id: ghi789 modifiedTime: 22:42
... (1日で25件)修正: file_id ではなく file_name + modified_time で重複チェックするように変更しました。同名ファイルが複数あれば最新の modifiedTime のものだけを処理し、以前取り込んだ記録があって modified_time が変わっていなければスキップします。
# 変更前:file_id で検索(毎回「新規」と判定される)
existing = drive_repo.find_by_file_id(child_id, file_id)# 変更後:file_name で検索(内容が変わったときだけ再インポート)
existing = drive_repo.find_by_file_name(child_id, file_name)
if existing and existing.modified_time == modified_time:
return FileSyncOutcome(status="skipped")これで、ぴよログがファイルを更新したとき(新しい記録が追加されたとき)だけ再インポートが走るようになりました。
1日の予定表示機能
ミルク・おむつの記録とは別に、「家庭の1日のルーティン」を表示する機能を作りました。少なくとも育休中はある程度赤ちゃんのお世話で、同じことを同じ時間でするように心がけると、赤ちゃんの泣くタイミングなどが安定し、対処しやすくなる印象があります。このため、今何をする予定なのかをぱっとわかるように表示するようにしました。予定は以下のようにYAMLで管理しています。
schedule:
- start_time: "08:00"
end_time: "08:50"
title: "朝のルーティン"
description: "おむつ交換・授乳・顔拭き・保湿"
category: "care"
priority: 1
- start_time: "20:00"
end_time: "04:00" # 翌日4時まで(日またぎ)
title: "夜間対応"
description: "授乳・おむつ交換など"
category: "care"
priority: 1このYAML自体は普段妻と共有している雑な予定表をClaude Codeに送り付けると簡単にYAMLに直してくれたものを利用しました。
ブラウザ通知(別アプリ作業中でも気付ける)
育休中は育児の合間に趣味のコーディングをしていることが多いです。ダッシュボードを開いていても、別のアプリが前面にある状態で予定の時間が来ても気づけません。このため、ブラウザの通知機能も付けました。通知機能をつけるにあたり、いろいろ選択肢がありますが、大体PCで何か作業をしていると思われますので、今回はシンプルなブラウザ通知を利用しました。
Streamlit マルチページアプリの罠
今回、開発に初めてStreamlitを利用しましたが、開発中に Streamlit 特有のハマりポイントがあったので記録しておきます。
@st.cache_resource と st.session_state の違い
@st.cache_resource:プロセスレベルのシングルトン。全セッション・全ページで共有されますst.session_state:セッション(ブラウザタブ)レベルの状態。ページをまたいでも保持されますが、新しいセッションでは空になります
問題:インポートページに直接アクセスするとスケジューラ状態が消える
app.py(ホームページ)でスケジューラを初期化し st.session_state["_drive_scheduler"] に格納していました。しかしインポートページ(4_import.py)に直接アクセスすると app.py が実行されないため、session_state にスケジューラが入らず、UI の「自動同期: 動作中」表示が消えてしまいます。
修正
スケジューラ初期化を独立したモジュール(_drive_scheduler.py)に切り出し、@st.cache_resource で管理します。app.py も 4_import.py も同じ関数を呼ぶだけにしました。
# _drive_scheduler.py
@st.cache_resource
def get_drive_scheduler():
... # プロセスで1回だけ実行される
# 4_import.py のトップレベル
if st.session_state.get("_drive_scheduler") is None:
from baby_dashboard.ui._drive_scheduler import get_drive_scheduler
st.session_state["_drive_scheduler"] = get_drive_scheduler()ページが実行されるたびにトップレベルで確認するため、どの経路でアクセスしても確実に初期化されます。
開発方法について
今回はほぼClaude Codeで開発しました。ちょっとした趣味のコードやblogでClaude Codeを利用することはありましたが、そこそこの規模のアプリを作るのは初めてだったのと、勉強がてらspeckitを使いました。他の作業の合間に作ったので少し時間がかかりましたが、Claude Code を使いながら実装し、トータル1日分くらいの時間で作れると思います。
speckitを使うのは始めてだったのですが、以下のような利点がありました。
- タスク分解までは比較的すぐに終わって、どのようなことをするつもりなのかぱっと修正がしやすい
- 実装をまとまった単位でまとめて行ってもらえるので、頼んでからそこそこの時間放置できます。このため、自分は脇で別の作業ができる
個人開発レベルでは結構よかった印象です。他にも色々似たようなものはあると思うので、もう少しまじめに比較とかしてみようかと思っています。
まとめ
ダッシュボードを家のサーバーで動かして数週間、確実に育児の引き継ぎがスムーズになりました。「最後の授乳から4時間20分」という情報がブラウザを開けばすぐ見えるのは地味に便利です。
スケジュール通知も、別の作業をしていて授乳時間を忘れそうになったときに助かっています。
今回のダッシュボードを作る過程で、ぴよログのデータはSQLiteに入っているので、今後他のことにも活用できればと思っています。
