PFNの最新LLM PLaMo 2 8BをGoogle ColabでLoRAで学習してみる
少し前になりますが、PFNが開発しているLLM、PLaMo 2の8Bモデル(事前学習モデル)が公開されました。こちら特殊なライセンスになっていますが、個人が使う分には商業利用も可能なライセンスで公開されています。
このモデルは事前学習モデルなので、そのままではChataGPTなどの普通の人が良く使うLLMと違ってうまく指示を聞くようになっていませんがSFTなどの事後学習を行えばいろいろなタスクをこなせるようにすることが可能です。
この記事では、このような事後学習のやり方の一つとしてGoogle Colabで比較的安く使えるL4というGPUを使って、LoRAという方法で学習するやり方を紹介します。
今回紹介するコードは以下のところにありますので、参考にしてください。
https://github.com/shu65/plamo-2-8b-lora-sft-example/blob/main/PLaMo_2_8B_LoRA_SFT.ipynb
目次
LoRAとは
LoRAとは「Low-Rank Adaptation」の略で、大規模言語モデルのような大きなモデルの学習を、メモリが小さいGPU1枚など小規模な計算機環境で学習するために提案された手法です。
具体的にはモデルの一部のLayerに対して低ランクの行列を導入し、低ランクの行列のみ学習することでモデル全体を学習するのと比べて非常に少ないメモリで学習できるようにしています。
このLoRAを使った学習はライブラリがそろっていることもあり、簡単なものはかなり短いコードで書くことができます。
PLaMo 2 8B のLoRA
ここからPLaMo 2 8BでLoRAを使って学習する方法を説明していきます。
PLaMo 2 8B 利用規約への同意
先ほども説明した通りPLaMo 2 8Bは特殊なライセンスということもあり、事前に同意しておく必要があります。
これにはまず、Hugging FaceのサイトのPLaMo 2 8Bのページに行きます。URLは以下の通りです。
https://huggingface.co/pfnet/plamo-2-8b
このページに行くとまだライセンスに同意していない場合は以下のようにライセンスの一部が表示されていると思います。
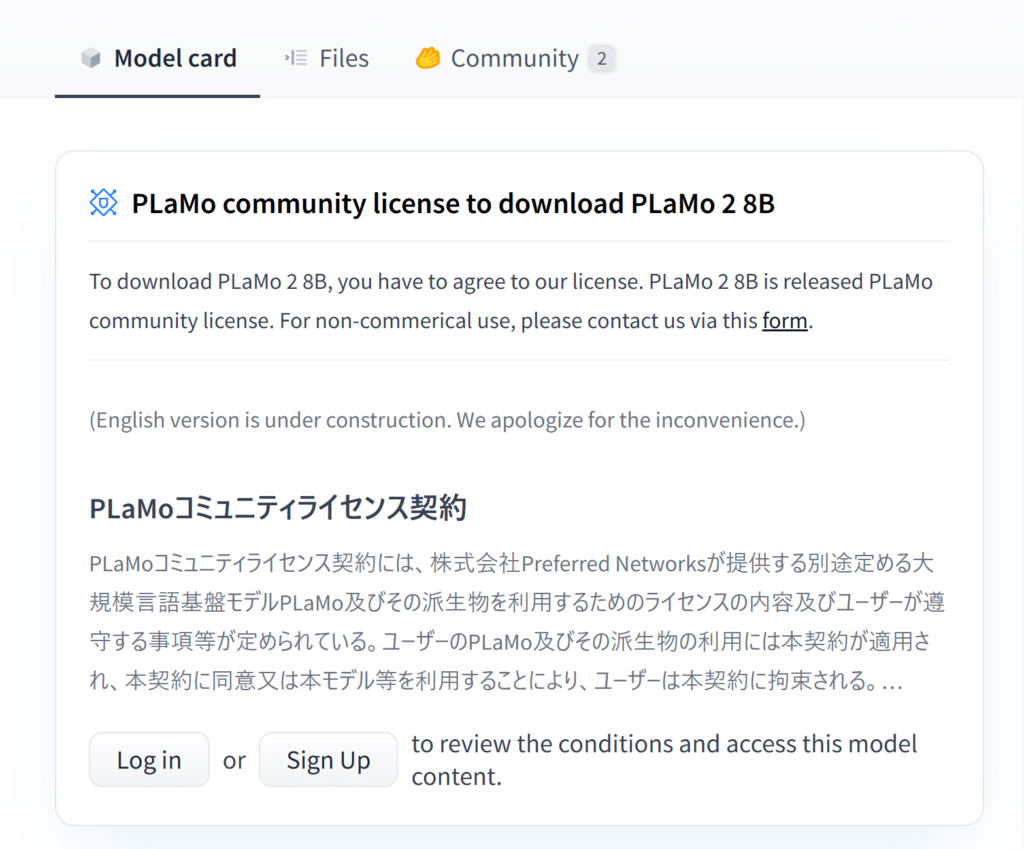
この場合はライセンスを確認の上、同意してください。同意すると以下のような表示になります。
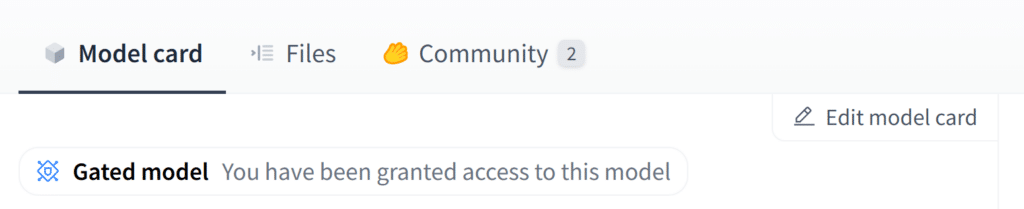
これでPLaMo 2 8Bを使う準備ができました。
Google ColabのランタイムでL4を使うようにする
次に、Google ColabでL4を使う準備をします。Google ColabでL4が使えるように課金が必要になりますので、まずは課金をします。
課金についてはこちらをご覧ください。
https://colab.research.google.com/signup?hl=ja
今回のコードを動かすだけであれば「Pay As You Go」で100 コンピューティング ユニットを購入すれば十分です。この記事を執筆時点では1200円に満たない程度で購入できます。
課金が済んだら、メニューバーから「ランタイム」→「ランタイムのタイプを変更」をクリックします。すると無料枠では選択できないL4 GPUが選択できるようになっていると思うので、L4 GPUを選択します。
これでGPUを使う準備ができました。
必要パッケージのインストール
次に今回の学習で必要なパッケージをインストールします。コマンドとしては以下の通りです。
!pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu124
!pip install trl numba>=0.60.0 mamba-ssm>=2.2.2 causal-conv1d>=1.4.0 transformers>=4.44.2最初にPytorchのバージョンを少し下げていますが、これはPLaMo 2の中で使われているライブラリの一部が最新のPyTorchに対応させるのが結構大変なため、簡単に実行できるようにするために少し古いPyTorchを入れています。
上記のコマンドを実行したあとは、以下のバージョンになっていました。
causal-conv1d 1.5.0.post8
mamba-ssm 2.2.4
numba 0.60.0
numba-cuda 0.2.0
sentence-transformers 3.4.1
torch 2.4.1+cu124
torchaudio 2.4.1+cu124
torchsummary 1.5.1
torchvision 0.19.1+cu124
transformers 4.50.0
LoRAのコード
パッケージをインストールしたら次は以下のようにHugging Faceにログインします。
from huggingface_hub import login
login()これを実行するとHugging Faceのtoken を聞かれますのでHugging Faceのtokeを入力してください。
次に各パッケージをimportしておきます。
from transformers import AutoModelForCausalLM
from transformers import AutoTokenizer
import datasets
import string
from trl import DataCollatorForCompletionOnlyLM
from trl import SFTConfig, SFTTrainer
from peft import LoraConfig
import torchそして、PLaMo 2 8Bのモデルとtokenizerを以下のようにロードします。
model_name = "pfnet/plamo-2-8b"
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)「PLaMo 2 8B 利用規約への同意」の部分の手順ができていなかったり、Hugging Faceのログインがうまくできていないと、この部分でエラーがでると思われます。その場合は利用規約の同意ができているかや、正しくHugging Faceのログインができているかなどを確認してください。
次に今回使うinstructionデータをダウウンロードして、前処理します。今回はkunishou/databricks-dolly-15k-ja のinputがないデータだけを取り出して利用します。
dataset = datasets.load_dataset("kunishou/databricks-dolly-15k-ja")
train_dataset = dataset["train"].filter(lambda data: "instruction" in data and "output" in data and data["input"] == "").select(range(2000))
data_collator = DataCollatorForCompletionOnlyLM(
response_template=tokenizer.encode(" Answer:\n", add_special_tokens=False),
tokenizer=tokenizer
)次にLoRAとSFTの引数を指定します。PLaMo 2特有の部分としてLoraConfig でLoRAを使って学習するレイヤーを指定するtarget_modules という引数があります。ここでLLaMa系のようなTransformerの場合、AttensionのQeury, Keyを作るLinearレイヤーをLoRAで学習することが多い印象なので、PLaMo 2でも同じようにAttensionのQueryとKeyを作るLinearレイヤーをLoRAで学習するようにします。PLaMo 2の場合は、Qeury, Key、Valueを作るLinearレイヤーをすべてまとめたqkv_proj というLinearレイヤーがありますので、このqkv_proj をtarget_modules に指定しています。
peft_config = LoraConfig(
task_type="CAUSAL_LM",
target_modules=[
"qkv_proj",
],
)
sft_args = SFTConfig(
output_dir="./outputs",
evaluation_strategy="no",
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=5e-5,
num_train_epochs=1.0,
lr_scheduler_type="cosine",
warmup_ratio=0.3,
logging_steps=10,
save_strategy="epoch",
report_to="tensorboard",
bf16=True,
max_seq_length=1024,
gradient_checkpointing=True,
)あとはデータのサンプルに対してフォーマットに合わせて1つのテキストを生成するformatting_func を定義します。今回は以下のようなものを使います。
INSTRUCTION_TEMPLATE = string.Template(
"""### Question:
{input} ### Answer:
{response}<|plamo:eos|>
"""
)
def formatting_func(example):
text = INSTRUCTION_TEMPLATE.substitute(input=example["instruction"], response=example["output"])
return text最後に、ここまで用意したものをSFTTrainer に渡して学習を開始します。
trainer = SFTTrainer(
model=model,
args=sft_args,
peft_config=peft_config,
data_collator=data_collator,
train_dataset=train_dataset,
formatting_func=formatting_func,
)
trainer.train()
trainer.save_model()
今回の設定では500イテレーション回ることになるはずです。私が試した限りは15分程度で処理が完了しました。
できたモデルの出力が正しいかは以下のコードで確認できます。
import torch
# プロンプトの準備
prompt = "### Question:\n埼玉の県庁所在地は何市?\n\n### Answer:\n"
# 推論の実行
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_tokens = trainer.model.generate(
**inputs,
max_new_tokens=64,
pad_token_id=tokenizer.pad_token_id,
)[0]
generated_text = tokenizer.decode(generated_tokens)
print(generated_text)おそらく以下のような出力がでるはずです
<|plamo:bos|>### Question:
埼玉の県庁所在地は何市?
### Answer:
さいたま市<|plamo:eos|>終わりに
いかがだったでしょうか?今回はPLaMo 2 8Bに対してLoRAによって学習する方法を紹介しました。LoRAを使えばメモリが少ないL4のようなGPUでも8Bモデル程度で学習することができます。今回のコードを使えば事後学習が簡単にできると思われますので、みなさんもいろいろ試していただければと思っています。無料枠で使えるGPUのT4でも量子化などを頑張れば8Bモデルも学習できる気がしますが、うまくできそうであればそちらも記事にしようと思います。
この他にもPLaMoを含めたLLMの技術も紹介できればと思っています。
