OptunaのPreferential Optimizationを使ったおいしいコーヒーの淹れ方探索
先日リリースされたOptuna 3.4にPreferential Optimizationという機能がついに入りました!
このPreferential OptimizationはOptunaとOptuna Dashboardによって、複数のtrialの出力のうちどれがよいかを人が判断して入力し、最適化していく機能です。
この機能がどういうときにうれしいかというと、コーヒーの味の良し悪しのような主観的な評価でしか評価できないとき、二つを比べてどちらがいいのかという評価で最適化を実行することができます。
以前書いたOptunaを使ったおいしいコーヒーの淹れ方を探索するときにはレシピごとに絶対評価のスコアをつける必要がありました。この絶対評価をつけるのがやっかいで、全体を通して矛盾のない評価を人がするのはかなり難しいと考えています。一方、Preferential Optimizationであれば、二つのレシピでどっちがおいしいかを比べればよいだけになり、簡単な評価で探索を行うことができるようになりました。
ちなみに以前のOptunaを使ったコーヒーの淹れ方はこちらになります。
今回の記事ではOptunaのPreferential Optimizationを利用してよりよくした新しくなった「おいしいコーヒーの淹れ方探索」の方法について紹介します。
今回のコードはこちらに上げてあります。
https://github.com/shu65/coffee_blog_2023
普段はGoogle Colabで動くようなコードを作るのですが、今回はOptuna DashboardというOptunaの探索結果をWebUIで確認できるツールもセットで使う必要があるため、localで動かすことを想定したコードを示します。
目次
Preferential Optimizationを使ったおいしいコーヒーの淹れ方の概要
OptunaのPreferential Optimizationを使う場合、コーヒーの淹れ方の探索するには以下の4つのステップを繰り返していきます。
- Optunaに2個になるまでtrial(コーヒーのレシピのこと)を提案してもらう
- 2つのレシピでコーヒーを淹れる
- 美味しくなかったほうがどちらなのかOptunaに登録する
- 次のレシピをOptunaに提案してもらい、2に戻る
Preferential Optimizationじゃない普通のOptunaの最適化との違いとしては次の通りです。
- 複数のtrialを提案
- trailごとにスコアを登録するのではなく、複数のtrailのどれが良いか、悪いかをOptunaに登録する
最初にも述べたようにPreferential Optimizationを使うことで絶対評価ではなく、相対的な評価でOptunaの探索ができようになります。
コーヒーを淹れるための道具
Optunaでコーヒーの淹れ方を探索してもらう際、どの道具を使うかで探索できるパラメータが変わります。Preferential Optimizationをするなら個人的には以下のものを使うのが良いと考えているので簡単に紹介します。
| 商品名 | 説明 |
| フラワードリッパー DEEP27 | 話題の1杯用のドリッパー。少量のコーヒーを淹れられるので1日に何杯もコーヒー飲むと気持ち悪くなる人も複数杯飲める |
| 山善 電気ケトル NEKM-C1280 | 温度が1度単位で60-100度まで指定可能。山善はモデルチェンジも早いので今買うなら最新のモデルを買うのがおすすめ |
| TIMEMORE X | 細かくコーヒーの挽き目調整ができる。調整も簡単なので使いやすい |
| TIMEMOREタイムモア Black Mirror nano | 重さ、時間だけじゃなく流量も測定できるスケール |
特徴的な道具として、今回はフラワードリッパー DEEP27を使いました。これは9月に発売したばかりの1杯用のドリッパーで、紹介されている記事や動画を見ると皆さん思い思いのレシピを公開している様子です。このため、個人的には何がいいのかわからん状態なので、探索するにはちょうどいいということで選びました。
実際のOptunaのパラメータ探索
ここからは実際にOptunaを使ったコーヒーの淹れ方のコードを説明していきます。
まずはどのように今回レシピを探索していくのか説明するためにベースとなる淹れ方から説明していきます。
ベースのレシピ
コーヒーのレシピの探索の前にベースとなるレシピを決めます。
ベースのレシピはかなり重要で、ベースとなるレシピに基づいてどの部分をOptunaで探索するかはもちろん、ベースのレシピが難しすぎると同じレシピでも味が不安定なったり、Optunaで探索するパラメータが多すぎてうまく探索できないということが起きます。
今回はかなり簡単に淹れることができる以下の「暮らしとコーヒー」のチャンネルの動画のレシピを参考にベースのレシピを作ります。
ベースのレシピは以下の通りです。
- 豆の量: 12g
- お湯の温度: 86℃
- 抽出量: 150g
- ミルのクリック数: 18
- 蒸らし時間: 20秒
- 蒸らしのお湯の量: 20g
今回のレシピは一定速度でお湯を注ぎ続ければよいので再現しやすいレシピかと思っています。さらに今回使ったスケールのように流量を見れるものであれば、同じレシピであれば毎回似たような味にすることができると思います。
探索するパラメータ
次にベースのレシピに基づいて探索するパラメータについて説明していきます。
基本はベースのレシピの値を中心にある程度の範囲を探索することにします。ただし、豆の量と抽出量に関してだけは二つを同時に探索するのではなく、抽出量を150gに固定したうえで、豆の量(g)/抽出量を探索することにします。こうすることで、探索する項目を一つ減らせ、またできるコーヒーの量が同じになるというメリットがあります。
また、お湯の量や時間は1g、1秒単位できっちりやるのは難しい印象です。このため、10g、5秒単位のようにある程度の幅で探索していきます。
上記のことをコードにすると以下のようになります。
temperature = trial.suggest_float("お湯の温度(℃)", 80, 95, step=1.0)
bean_per_water = trial.suggest_float("豆の量 (g)/お湯の量(g)", 0.053, 0.1, step=0.01) # 8/150-15/150
click_count = trial.suggest_float("ミルのクリック数", 16, 24, step=1.0)
steaming_time = trial.suggest_float("蒸らし時間(sec)", 0, 40, step=5.0)
steaming_water_weight = trial.suggest_float("蒸らしのお湯の量(g)", 10, 30, step=10.0)update 2024/02/28: suggest_int() と suggest_float() が混ざっていると一部のパラメータが毎回同じ値になってしまったのですべて suggest_float() に変更し、step を指定するように変更しました。
これに加えて必ず探索してほしいパラメータとして、ベースのレシピに基づく値をenqueue_trial() で入れておきます。何もしないと、最初から完全にランダムなレシピで探索してしまい、まともなレシピが出てくるまで時間がかかる印象です。このため、一つはまともなレシピを最初に入れておくと、まともなレシピと新しく提案されたレシピの二つを比べるような状態になるので、最初のほうは楽に比較ができる印象です。
コードとしては以下のようになります。
if len(study.get_trials()) == 0:
# add default trial.
# ref: https://www.youtube.com/watch?v=G7vxam3T5mQ&t=68s
params = {
"お湯の温度(℃)": 86,
"豆の量 (g)/お湯の量(g)": 12/150,
"ミルのクリック数": 18,
"蒸らし時間(sec)": 20,
"蒸らしのお湯の量(g)": 20,
}
study.enqueue_trial(params)Optuna Dashboardで表示するnoteの生成
次に新しいtrialで提案されたパラメータをOptuna Dashboardで表示する部分です。今回は提案されたパラメータからレシピ文章を作り、noteに追加し、noteをOptuna Dashboardで表示するということをします。このnoteの内容を見てコーヒーを淹れることになるので、以下のことを意識してnoteにレシピをまとめることにします。
- 提案された値が必要になる順にnoteに列挙する
- 探索は豆の量 (g)/お湯の量(g)だが、実際に必要なのは豆の量なので、豆の量を計算してnoteに列挙する
特に重要なのが1で、コーヒーを淹れる際、例えばお湯を沸かすのは時間がかかるので、最初にお湯の温度が必要になります。これがれnoteの真ん中にあると少し手間取ります。このため、最初に書いてあると私の経験上スムーズなので、お湯の温度は最初に出力します。他のパラメータも同様に必要になる順番で列挙していくことでコーヒーをスムーズに淹れることができ、また間違いが減らせる印象です。
コードとしては以下の通りです。
bean_weight = int(bean_per_water*water_weight)
note = textwrap.dedent(
f"""\
## レシピ
- お湯の温度(℃): {int(temperature)}
- ミルのクリック数: {int(click_count)}
- 豆の量(g): {int(bean_weight)}
- 蒸らしのお湯の量(g): {int(steaming_water_weight)}
- 蒸らし時間(sec): {int(steaming_time)}
- 抽出量(g): {int(water_weight)}
"""
)
save_note(trial, note)複数trialの提案
先ほどまでのパラメータ探索部分は従来のOptunaとほぼ同じでした。ここからPreferential Optimizationのときに必要な部分について説明していきます。まずは複数trialの提案部分です。
Preferential Optimizationは複数のtrialをOptuna Dashboard上でどちらが良かったのかを記録していくので、コード的には新しいtrialを作るask() を呼んでパラメータを提案させるところまでやり、tell() を呼びません。そして比較のときに必要なtrialの数に足りなければ次のtrialを作り、十分な数があれば待つという動作をすることになります。
コードとしては以下の通りです。
STORAGE_URL = "sqlite:///example.db"
study = create_study(
n_generate=2,
study_name="GUATEMALA recipe",
storage=STORAGE_URL,
sampler=PreferentialGPSampler(seed=42),
load_if_exists=True,
)
register_preference_feedback_component(study, "note")
# add default parameters
...
while True:
if not study.should_generate():
time.sleep(0.1) # Avoid busy-loop
continue
trial = study.ask()
# Ask new parameters
...
# Add note
...実行方法
ここまでのコードを組み合わせたrecipegenerator.py とOptuna Dashboardを組み合わせて実行します。それぞれ以下のように実行します。
python recipe_generator.py &
optuna-dashboard sqlite:///example.dbこれで http://127.0.0.1:8080/dashboard/studies/1/ にアクセスして以下のような画面がでてくれば成功です。
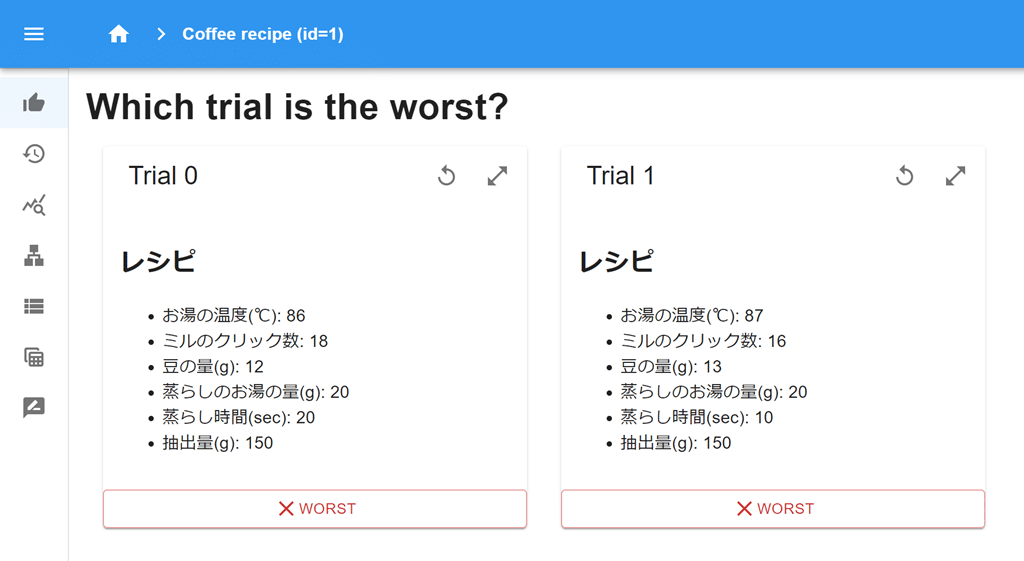
Trial 0 が最初に入れたベースのレシピ、Trial 1がOptunaが提案してきた新しいレシピになります。あとはこのレシピに従ってコーヒーを淹れて評価して、美味しくなかったほうを「WORST」にしてまたコーヒーを淹れるというのをひたすら繰り返すだけです。
終わりに
今回はPreferential Optimizationを使ったコーヒーのレシピ探索について書きました。Optunaのデフォルトだと10回まではランダム探索で、まだ探索を開始してから1週間なので実はまだランダム探索の状態です。これから実際に探索が行われてからどうなるか楽しみです。
ある程度探索できたらデータを解析して記事にしようと思います。
