CUDAの高速化の復習2023年版 Vectorized Memory Access編
前回Reductionを例に今時のCUDAの高速化で何が効いているのか?を確認したまとめの記事を書きました。今回はその中には登場しなかったCUDAの高速化テクニックの「Vectorized Memory Access」が今でも有効なのか確認したまとめになります。
このvectorized memory accessは昔からあるテクニックです。ただ、最近CUDAの高速化をしようとして、vectorized memory accessを試してみるのですが、いまいち効果がなさそうな気配があったので、ちゃんと調べようと思い今回記事をかきました。ちなみに結論からいうと今でもちょっとは効果ありそうでした。
検証に利用したコードはこちらにあげてあります。
https://github.com/shu65/cuda-vectorized-memory-access
検証環境はCUDA 12.0、GPUはA100を使っています。
今回のVectorized Memory Accessは少しマニアックなテクニックなので、CUDAの高速化全般に関して簡単に知りたいという方はReductionの記事のほうがおすすめです。リンクは以下の通りです。
Vectorized Memory Accessとは?
Vectorized Memory AccessとはCUDAにおいて連続するグローバルメモリへのアクセスを高速化するテクニックの一つです。このテクニックは結構昔から知られていてNVIDIAのblogでも2013年に紹介されています。
https://developer.nvidia.com/blog/cuda-pro-tip-increase-performance-with-vectorized-memory-access/
詳細はこちらのNVIDIAの記事を見ていただきたいと思いますが、ざっくり簡単に説明すると、連続したグローバルメモリにアクセスする際にintなど32 bit単位でアクセスするよりもint2やint4でアクセスするほうが速いよ、というものです。int2、int4はCUDAで定義されている構造体でintを2つ、または4つもった構造体です。なので、普通のintが32 bitなのにたいしてint2だと64 bit, int4だと128 bitのサイズになってintよりも大きいデータに一気にアクセスすることになります。
Vectorized Memory Accessの検証コード
今回、配列の要素数を1Kから1Gまで増加させたとき、配列の全要素を別の配列にコピーする単純なカーネルで測定します。Vectorized memory accessを使わない場合は以下のようなコードになります。
template <typename T>
__global__ void CopyScalarKernel(T *d_in, T *d_out, const size_t n)
{
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
const int stride = blockDim.x * gridDim.x;
for (int i = idx; i < n; i += stride)
{
d_out[i] = d_in[i];
}
}
template <typename T>
void CopyScalar(T *d_in, T *d_out, size_t n)
{
int max_blocks = 4096;
int threads = 1024;
int blocks = min((int)(n + threads - 1) / threads, max_blocks);
CopyScalarKernel<T><<<blocks, threads>>>(d_in, d_out, n);
}thread数やblock数を変化させるとパフォーマンスが若干変化するのですが、ここのチューニングするのは大変なので、すべて同じ方法で決めて使います。
このコードでvectorized memory accessを使って64 bit, 128 bitでアクセスするときはこのようなカーネルになります。
template <typename T>
__global__ void CopyVector2Kernel(T *d_in, T *d_out, const size_t n)
{
const float ratio = ((float)sizeof(int2)) / sizeof(T);
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
const int stride = blockDim.x * gridDim.x;
const int m = n / ratio;
for (int i = idx; i < m; i += stride)
{
reinterpret_cast<int2 *>(d_out)[i] = reinterpret_cast<int2 *>(d_in)[i];
}
}template <typename T>
__global__ void CopyVector4Kernel(T *d_in, T *d_out, const size_t n)
{
const float ratio = ((float)sizeof(int4)) / sizeof(T);
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
const int stride = blockDim.x * gridDim.x;
const int m = n / ratio;
for (int i = idx; i < m; i += stride)
{
reinterpret_cast<int4 *>(d_out)[i] = reinterpret_cast<int4 *>(d_in)[i];
}
}重要な点として、グローバルメモリからデータと読み込むときと書き込むときでint2やint4など大きい型のポインタにキャストしてからアクセスするということをしています。
Vectorized Memory Accessの結果
では、さきほどのコードを動かして実際にどのくらいのスループットになるかを示します。計測する際は10回の平均時間を出してスループットを算出しました。比較には最近よく使う、halfの配列とfloatの配列の2種類を使います。そしてデータにアクセスするときは、何もしないscalerのまま、32 bit, 64 bit, 128 bitでアクセスする場合の合計4つを示します。
halfとfloatの結果のグラフを以下に示します。
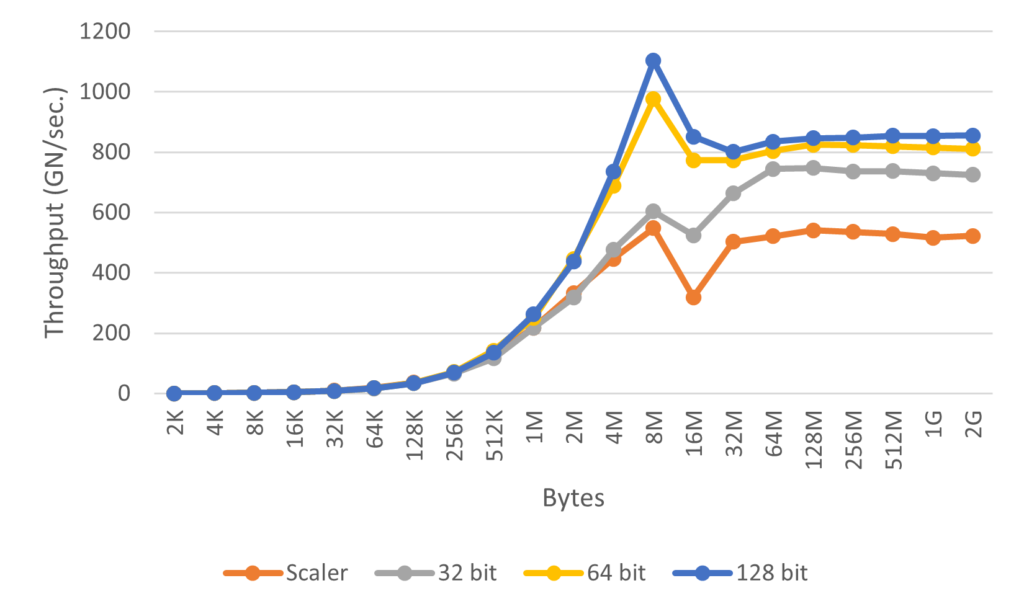
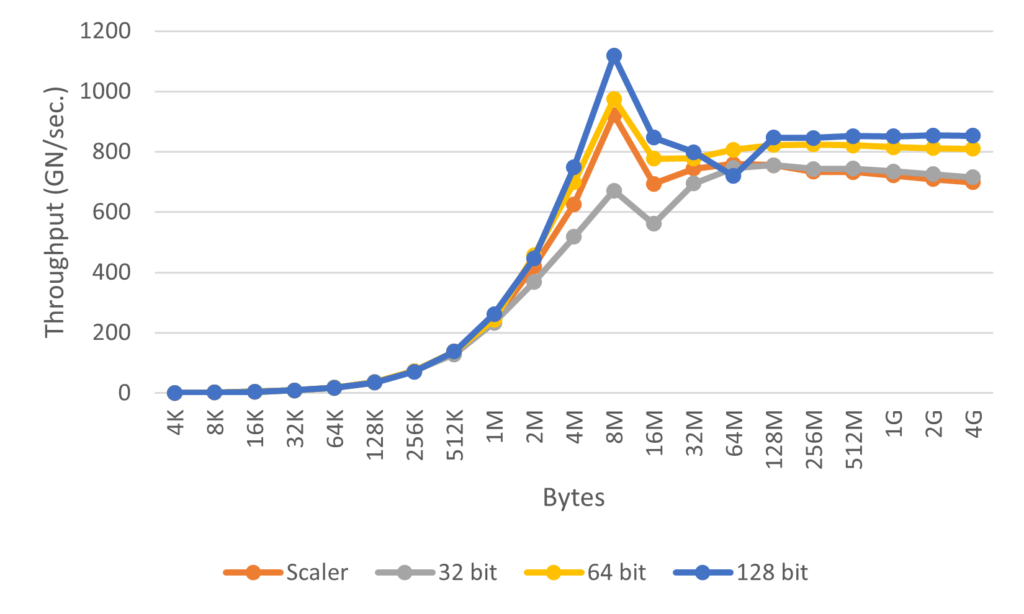
結果を見るとコピーするサイズが小さいときはvectorized memory accessなし、ありでそれほど差がなく、数MBくらいでちょっとずつ差がでるという感じの結果でした。ちなみにfloatで32bitでアクセスするとscalerよりも遅くなっていますが、これはキャストのオーバーヘッドがあるためだと思われます。
やってみた感想としては今も多少は効果があるけど、そこまで劇的に変化するわけではなさそうという印象です。なので、最適化をできるだけ頑張って、もう次やることがないってなったときに試してみるくらいでよいかなということを思いました。
終わりに
今回は昔からあるCUDAの高速化テクニックの一つのvectorized memory accessが今でも有効なのか確認したので、そのまとめを書きました。CUDAのコンパイラやGPUのアーキテクチャもどんどん変化しているので、昔は効果あったけど今はない、ってものも少なからずあるので、今後もこういう高速化テクニックの確認をしていければと思います。
