Optunaを使ったおいしいコーヒーの淹れ方探索 (2021年4月版)
昨年終わりに機械学習のハイパーパラメータ探索で良く用いられるOptunaを使って、おいしいコーヒーの淹れ方を探索する方法についてQiitaの記事を書きました。この記事が思ったよりも好評で、これをきっかけに勉強会でも発表させていただきました。ただ、やっているうちに以下のようなことを考えるようになりました。
- Optunaのドキュメントにはないprivateな関数を使って無理やり実装していて微妙
- 味に影響する重要なパラメータが使っていた道具の影響で探索できていなかった
- 探索させるパラメータを工夫したほうが良かった
今回はこれらを解決した今現在の2021年4月版のコーヒーの淹れ方の探索を紹介していきたいと思います。Qiitaの記事を読んでない方も多くいらっしゃると思うので、この記事では最初から説明をしていきます。
目次
コーヒーの淹れ方の探索方法の概要
Optunaを使ったコーヒーの淹れ方の探索では以下の4つのステップを繰り返すことで実現します。
- 過去のコーヒーの淹れ方とその時の評価値をOptunaに登録
- 過去の淹れ方の履歴を基に次に試すべき淹れ方をOptunaで提案
- 提案された淹れ方を実際に試して味を評価
- Optunaが提案したパラメータと評価値を記録(今回はGoogleスプレッドシートを利用)
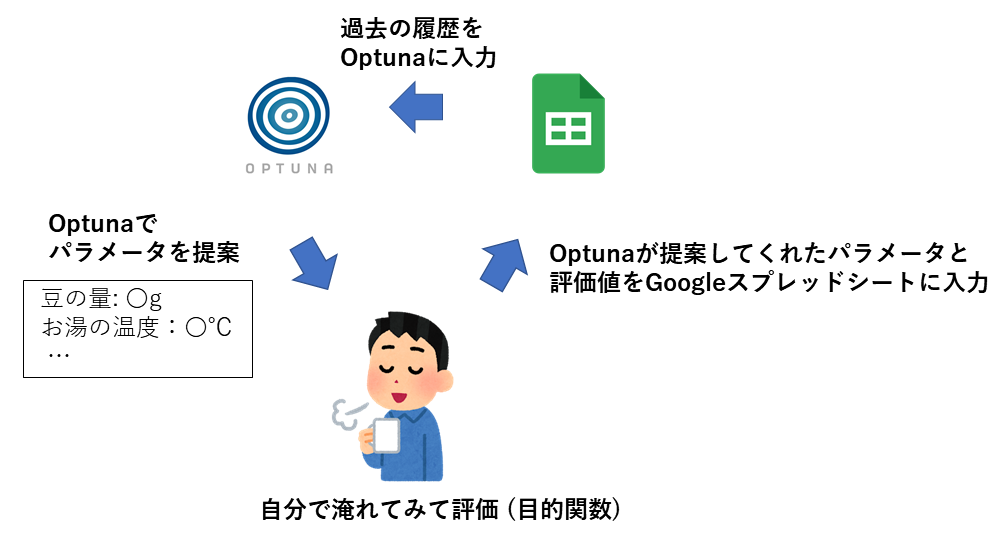
普通のOptunaを利用例の場合、すべてコンピューター上で完結させますが、今回は人力(3の部分)があるのが特徴的です。
ただ、この特徴的な3の部分の所為で、前回のQiitaの記事ではOptunaのprivateな関数を使って実装せざるをえませんでした。しかし、v2.5.0で追加されたAsk-and-Tellのask()でこの問題が解決されました。この記事ではAsk-and-Tellも簡単に紹介していきたいと思います。
v2.5.0のリリースで追加されたAsk-and-Tellは、簡単にいえばOptunaのパラメータの提案する部分 (ask())とOptunaに提案されたパラメータのスコアを教える部分(tell())の2つの部分に分けて実行するためのAPIです。
これにより、従来は面倒だった、あるプロセスでパラメータを提案させて、その後、別のプロセスでスコアを計算してOptunaに登録するというような分離が簡単に書けるようになりました。今回のコーヒーの淹れ方の場合は、パラメータの提案とスコアを出すところがコンピュータ上での実行と人力とで別れているため、このAsk-and-TellはぴったりなAPIになっています。
より詳しくAsk-and-Tellについて知りたい方はOptunaのリリースノートをご覧ください。
Optunaで探索する上で必要なものとコーヒーの淹れ方の場合の例
Optunaでパラメータの探索をする際には主に以下の二つが必要になります。
- パラメータ毎の探索空間
- 提案されたパラメータを受け取って目的変数の値を返す目的関数
パラメータ毎の探索空間とは提案をしてほしいパラメータ毎に提案をしてほしい値の範囲を指定したものになります。Optunaがよく使われているニューラルネットワークの例で言うと、以下のようなものになります。
| パラメータ | 探索範囲 |
| 隠れ層のユニット数 | 1-128 |
| 学習率 | 0.001-1.0 |
また、目的関数とは、指定されたパラメータで学習した結果の精度を返す関数となります。
では、コーヒーの淹れ方の場合はパラメータに対応するものと、目的関数をどうすればよいでしょうか?
後ほど詳しく紹介しますが、今回はパラメータとして豆の量やお湯の温度など、コーヒーの淹れ方で重要なものをパラメータとして扱います。探索範囲は各パラメータ毎に基準とした値を中心にして現実的な範囲で広げたものを利用します。
また、目的関数ですが、実際に提案されたパラメータに基づいて自分でいれて、おいしかったかどうかを自分で1-10点で評価して返すという人力のものを利用します。
現在のコーヒーの入れる環境
使う道具によってパラメータとして扱えるものが変化するので、使う道具についても紹介します。
今回は以下の道具で淹れるとして紹介しています。
- ミル: ポーレックス コーヒーミル・Ⅱ (調節ねじのクリック数によってコーヒーの粒度を変えられる)
- ポット:山善 電気ケトル NEKM-C1280 (温度設定可能)
- 抽出器: BODUM CHAMBORD(フレンチプレス)
前回との大きな変更はミルとポットです。ミルのほうは粒度が安定するようなものに変えました。また、ポットのほうは以前のものだと温度調節ができなかったのですが、温度調節ができるものに変更しました。これにより、コーヒーの粒度の安定性が増し、再現性があがったのに加え、コーヒーで重要なお湯の温度を制御できるようになりました。
また、今回もフレンチプレスを使ったコーヒーの抽出を行います。コーヒーを淹れる方法として有名なものはペーパードリップだと思いますが、ペーパードリップは探索したほうがよさそうなパラメータが多すぎるのと、お湯の注ぎ方など素人では安定させるのが難しい要素が多いという問題があります。このため、素人でも安定して入れられるフレンチプレスを利用します。
フレンチプレスを使った淹れ方をご存知ない方に簡単に説明すると
- 挽いた豆をフレンチプレスの中に入れる
- (少量のお湯を入れてしばらく置いて蒸らす)
- お湯を入れる
- (スプーンかき回す)
- 時間になったら金網フィルターを下ろして完成
という流れでコーヒーを抽出します。カッコのところは、淹れ方の説明をいろいろ読むとあったりなかったりする部分です。
もっと詳しく知りたいという方はこちらのページを参考にしてください。
実際のOptunaのパラメータ探索
ここからは実際にOptunaを使ったコーヒーの淹れ方のコードを説明していきます。今回のコードはこちらに上げてあります。
https://github.com/shu65/coffee-tuning/blob/main/coffee_tuning_2021_04.ipynb
計算環境
環境としては手軽にできるようにということで以下のサービスを利用します。
- プログラム実行:Google Colab
- データ管理:Google スプレッドシート
Optunaの探索範囲
今回は基準となる淹れ方を決め、それにある程度範囲を持たせたものを探索範囲とします。
本やネットを参考にして以下のような値を今回の基準としました。
- 豆の量 (g): 9
- ミルのクリック数: 15
- お湯の温度(℃):92
- 抽出時間 (sec): 240
- 蒸らし時間 (sec): 30
- お湯の量 (g): 200
さて、これを基準にプラスマイナスいくつかの範囲で探索すればいいのですが、豆の量とお湯の量に関しては少し工夫をします。
今回はお湯の量を200gに固定して、「豆の量 (g) / お湯の量 (g)」 という値をOptunaでは探索します。一時期、お湯の量も毎回探索していたのですが、お湯の量を変えると、できるコーヒーの量も変化してしまうという問題がありました。これを防ぐためにお湯の量を固定して、それに合った豆の量をOptunaに提案してもらうという形とするために「豆の量 (g) / お湯の量 (g)」を提案してもらいます。このように豆の量とお湯の量の比にして探索しておくと、お湯の量が微妙に変えたくなったときの探索にも今のデータをそのまま活用することができます。
以上に加え、蒸らしがあったほうがいいかととスプーンでかき混ぜたほうがいいかも探索させます。
これをまとめると以下のような探索範囲になります。
- 豆の量 (g) / お湯の量 (g): 0.038-0.08
- ミルで豆を挽く時間 (sec): 4-24
- お湯の温度(℃):80-99
- 抽出時間 (sec): 180-300
- スプーンでかき混ぜる:あり or なし
- 蒸らし:あり or なし
- 蒸らし時間 (sec): 20-40
Google スプレッドシートによるデータのまとめ方
淹れ方とその時の評価値 (スコア) をまとめる方法として今回はGoogle スプレッドシートを利用しました。表としてはこのような形です。

Optunaで使わない値に関しても後々のデータ解析ように入れてあります。
Optunaによるパラメータ提案
ここまで準備できればいよいよOptunaで探索範囲に従ってコーヒーの淹れ方を提案してもらいます。
この部分の基本的な流れとしては以下の通りです。
- 過去のコーヒーの淹れ方とその時の評価値をOptunaに登録
- 過去の淹れ方の履歴を基に次に試すべき淹れ方をOptunaで提案
順番に説明していきます。
1. 過去のコーヒーの淹れ方とその時の評価値をOptunaに登録
まず、過去のコーヒーの淹れ方とその時の評価値をOptunaの Study に登録していきます。
最初にGoogleスプレッドシートからデータを取ってきます。コードとしては以下の通りです。
# Google スプレッドシートの承認
from google.colab import auth
from oauth2client.client import GoogleCredentials
import gspread
auth.authenticate_user()
gc = gspread.authorize(GoogleCredentials.get_application_default())
# スプレッドシートからデータを取ってくる
import numpy as np
import pandas as pd
ss_name = "mattari-benkyo-note coffee tuning 202104"
workbook = gc.open(ss_name)
worksheet = workbook.get_worksheet(0)
df = pd.DataFrame(worksheet.get_all_records())
df[df == ''] = np.nan
df['かき混ぜる'] = df['かき混ぜる'].astype(np.bool)
df['蒸らし'] = df['蒸らし'].astype(np.bool)
df = df.set_index('淹れた日')
dfGoogle スプレッドシートの承認をしたあと、0番のシートから情報を取ってきて、pandasのDataFrameにするということをしています。その後適切な値や型の変換をします。
その後、読み込んだデータをOptunaのStudyを作り、add_trial() を使って登録していきます。
import optuna
study_search_space={
"豆の量 (g)/お湯の量(g)": optuna.distributions.UniformDistribution(0.025, 0.08),
"ミルのクリック数": optuna.distributions.IntUniformDistribution(4, 26),
"抽出時間 (sec)": optuna.distributions.IntUniformDistribution(180, 300),
"かき混ぜる": optuna.distributions.CategoricalDistribution([True, False]),
"蒸らし": optuna.distributions.CategoricalDistribution([True, False]),
"蒸らし時間 (sec)": optuna.distributions.IntUniformDistribution(20, 40),
"保存方法": optuna.distributions.CategoricalDistribution(["冷凍", "冷蔵"]),
"お湯の温度(℃)": optuna.distributions.IntUniformDistribution(80, 99),
}
score_column = 'スコア'
sampler = optuna.samplers.TPESampler(multivariate=True, n_startup_trials=10)
study = optuna.create_study(direction='maximize', sampler=sampler)
for record_i, record in df.iloc[::-1].iterrows():
is_record_null = record.isnull()
params = {}
trial_search_space = {}
for key in study_search_space.keys():
if not is_record_null[key]:
params[key] = record[key]
trial_search_space[key] = study_search_space[key]
if not is_record_null[score_column]:
try:
trial = optuna.trial.create_trial(
params=params,
distributions=trial_search_space,
value=record[score_column])
study.add_trial(trial)
except ValueError as e:
print("pass trial:", trial)
print(e)
print("sample size:", len(df))Study に登録する際もパラメータの分布が必要になりますが、これは提案するときの分布とは別ものです。add_trial() する際の注意点としてはadd_trial()のparamsに入っているパラメータの値がdistributionsで指定した探索範囲外だとエラーになります。時々お湯を少し多く入れてしまうというようなミスがあるので本来探索するよりも一部広い範囲を利用しています。
2. 過去の淹れ方の履歴を基に次に試すべき淹れ方をOptunaでパラメータで提案
さて、いよいよOptunaのAsk-and-Tellのask() を使ってパラメータを提案していきます。
trial = study.ask()
new_params = {}
new_params["蒸らし"] = trial.suggest_categorical("蒸らし", [True, False])
if new_params['蒸らし']:
new_params["蒸らし時間 (sec)"] = trial.suggest_int("蒸らし時間 (sec)", 20, 40)
new_params["豆の量 (g)/お湯の量(g)"] = trial.suggest_uniform("豆の量 (g)/お湯の量(g)", 0.038, 0.08)
new_params["ミルのクリック数"] = trial.suggest_int("ミルのクリック数", 4, 24)
new_params["抽出時間 (sec)"] = trial.suggest_int("抽出時間 (sec)", 180, 300)
new_params["かき混ぜる"] = trial.suggest_categorical("かき混ぜる", [True, False])
new_params["お湯の温度(℃)"] = trial.suggest_int("お湯の温度(℃)", 80, 99)
# わかりやすい順番で表示
water=200
for key in ["お湯の温度(℃)", "豆の量 (g)/お湯の量(g)", "豆の量(g)", "ミルのクリック数", "かき混ぜる", "蒸らし", "蒸らし時間 (sec)","抽出時間 (sec)"]:
if key in new_params:
if key == "豆の量 (g)/お湯の量(g)":
beans = int(water * new_params[key])
print(key, new_params[key], beans / water)
print("豆の量 (g)", beans)
else:
print(key, new_params[key])</code></pre>これでコーヒーの淹れ方のパラメータを提案できます。試しに現状のパラメータで提案させると次のような結果が得られました。
お湯の温度(℃) 88
豆の量 (g)/お湯の量(g) 0.05400951154389384 0.05
豆の量 (g) 10
ミルのクリック数 9
かき混ぜる True
蒸らし True
蒸らし時間 (sec) 24
抽出時間 (sec) 205すでに約40trial分のデータがあるので、それっぽいものを提案してきている印象です。
あとは実際に入れてみて評価値をGoogle スプレッドシートに入れて次の提案に活かすということを繰り返しおこなっていくことで、徐々においしいコーヒーの淹れ方を提案してくれるようになります。
実際に3か月やってみた感想
実際に3か月やってみた印象としては、本やネットで調べたものよりもおいしい淹れ方が見つかった印象です。別の記事でデータ解析した結果の際にも紹介すると思いますが、酸味が強い豆と苦味が強い豆とではおいしいと思うパラメータが違うため、この辺りを素人がいろいろ探索する際には役立つかなと思っています。
ただ、コーヒーに詳しい方はおいしくない時にどう変更すればわかるような場合も多いと思われるため、そういう方は必要ないかなという印象です。
あとは、ネットや本で調べた知識に基づくと絶対変というような淹れ方になるときも当然あるのですが、「こんな味になるのか」という驚きがあって面白かったです。
現状でも残っている課題としては、おいしさをどう評価値にするかの部分かなと思っています。味はその日の体調やコーヒーのちょっとした温度の違いでも変化してしまいます。また、実際に同じタイミングで飲み比べているわけではないので、どうしても絶対評価が難しいという問題があります。この部分もいずれ解決できればと思っています。
終わりに
2021年度4月版のOptunaを使ったおいしいコーヒーの淹れ方の探索について紹介しました。
昨年末のころと比較して、大筋はそれほど変化してませんが、使う道具やその道具を使って何のパラメータをOptunaで提案させるかの部分はかなり変化した印象です。
そのうち、Optunaの可視化機能の紹介やそれらを活用したデータ解析を実際の3か月分のデータに適用した記事も書ければと思っています。また、現在はペーパードリップで同じように探索できないか挑戦していますので、そちらもある程度形になったら紹介記事を書きたいと思っています。

とても参考になりました。
2つ質問させてください。ご教授頂けると嬉しいです。
Q1
Optunaで制約条件をかけるにはどうすれば良いですか?
例えば、蒸らし時間と抽出時間の合計が必ず230秒になるようにしたい場合です。
Q2
提案されたパラメータをcsvファイルに書き出すにはどうしたらいいですか?
以上、宜しくお願い致します。
コメントありがとうございます!
> Q1
2変数の合計を制限したい場合であれば、以下のようにすればOKかと思います。3変数以上であれば、動的にoptunaのsuggest_int()の範囲を変えて対応するなどでいけると思います。
total_time = 230
new_params["蒸らし時間 (sec)"] = trial.suggest_int("蒸らし時間 (sec)", 20, total_time)
new_params["抽出時間 (sec)"] = total_time - new_params["蒸らし時間 (sec)"]
> Q2
CSVで出力したいのであれば、現状Pythonのdictになっているので、それをpandasのDataFrameにして、pandas の DataFrameの機能でcsvに出力させるのがコード量が少なくて楽かと思います。
こんな感じかと(コメント機能だとちゃんとインデントが指定できないので、適宜修正してください)
df_dict = {}
for k, v in new_params.items():
df_dict[k] = [v]
pd.DataFrame(df_dict).to_csv("params.csv")
Shu様
丁寧な回答ありがとうございます。
とても勉強になります。
>3変数以上であれば、動的にoptunaのsuggest_int()の範囲を変えて対応すると思います。
まさに実際は3変数以上なんです。
材料の原料が30種類あり、それぞれ体積含有率の範囲が異なります。
原料1:0~20%
原料2:0~20%
原料3:0~10%
原料4:0~10%
原料5:0~5%
原料6:0~5%
・
・
原料29:0~10%
原料30:0~10%
となっている場合に、原料1~原料30の合計が100%になるように、パラメータが提案される必要があります。
このような場合の方法(動的にoptunaのsuggest_int()の範囲を変えて対応する)をご教授頂けませんか?
以上、宜しくお願い致します。
以下のようにやればパラメータの提案自体はできます。
remaining = 100
x1 = trial.suggest_int(“x1”, 0, min([20, remaining]))
remaining -= x1
x2 = trial.suggest_int(“x2”, 0, min([20, remaining]))
remaining -= x2
…
ただ、30個もパラメータがあると、この方法では最後のほうの原料が0ばかりになってしまって、実際にやりたい最適化にはならない気がしています。
ここまでパラメータが多い場合どうするか、あまり私のほうに知見がないので、optunaを実際に開発している方達に聞いてみるとよいかと思います。
Githubのissueに投稿すれば、Optunaの開発メンバーは親切な方が多いので答えてくれると思います。
Optunaのissueはこちらです。
https://github.com/optuna/optuna/issues
shu様
ありがとうございました。
Optunaのissueでも聞いてみようと思います。
この記事面白いですねー
こんな風に分析につかうんですね。自分は淹れ方によりあまり味が左右されにくいフレンチプレスで淹れているので
なーんも考えてなかったですわ 毎日飲んでいるから、真似してみようかな